Overview and Summary
Roughly a months has passed since I wrote my first post on the Bridges to Prosperity Project. For anyone interested, the previous post can be found here. And since I’m not expecting anyone to go back and read an entire article just so that everything else makes sense, here a brief summary.
Bridges to Prosperity is a nonprofit organization that helps build footbridges in east african communities such as Rwanda. They have collected lots of data about various Rwandan villages and bridge sites, and have approached as with a request to help with building a tool allowing for the visualization of current and future bridge sites, with the inclusion of a predictive model determining and assess potential sites with a high social-economic impact on rural communities in the region.
At the beginning of the project we have been provided with extensive data sets on site assessments, as well as Rwandan administrative data, which ended up required tremendous amounts of preparation and cleaning in order to be merged into a single workable dataset.
While my fellow DS colleagues took on the responsibility of data cleaning and merging, I took on more of a dev-ops role, focusing on setting up the API and providing data endpoints for the use by our web teams.
These initial endpoint served as static data dumps, utilizing a simple DataFrame to JSON object conversion, and generally looked something like this,
# Package imports
from fastapi import APIRouter
import pandas as pd
import json
router = APIRouter()
# Loading Dataset
names_codes = "https://raw.githubusercontent.com/Lambda-School-Labs/Labs25-Bridges_to_Prosperity-TeamB-ds/main/data/edit/Rwanda_Administrative_Levels_and_Codes_Province_through_Village_clean_2020-08-25.csv"
# Converting to dataframe using pythons Pandas library
names_codes = pd.read_csv(names_codes)
# defining a function to set up the /villages endpoint
@router.get("/villages")
async def villages():
output = names_codes.to_json(orient="records")
parsed = json.loads(output)
return parsed
and the returning output like this:
{
"Unnamed: 0": 0,
"Prov_ID": 2,
"Province": "Southern Province",
"Dist_ID": 22,
"District": "Gisagara",
"Sect_ID": 2205,
"Sector": "Kigembe",
"Cell_ID": 220501,
"Cell": "Agahabwa",
"Vill_ID": 22050101,
"Village": "Agahehe",
"Status": "Rural",
"FID": 1842
},
...
Release 2 and Technical Challenges
While we generally made a lot of progress and were able to deliver on all requirements for RELEASE 1, the data merging aspect of this project turned out to be more challenging that we initially anticipated. Due the nature of the data, use of standard merge functions and workflows was not possible and we were required to come up with a decision tree like workflow in order to account for all the numerous edge cases and data inconsistencies.
Below a summery decision tree for a quick overview of the overall process:
Once we managed to finally merge the data as far as possible, the next challenge was setting up endpoint functions which return the agreed upon data format and structure to allow easier integration with the web-backend API.
For this purpose I have set up an /final-data endpoint returning merged data following the agreed upon format.
{
"project_code": "1014328",
"province": "Southern Province",
"district": "Kamonyi",
"sector": "Gacurabwenge",
"cell": "Gihinga",
"village": "Kagarama",
"village_id": "28010101",
"name": "Kagarama",
"type": "Suspension",
"stage": "Rejected",
"sub_stage": "Technical",
"Individuals_directly_served": 0,
"span": 0,
"lat": -1.984548,
"long": 29.931428,
"communities_served": "['Kagarama', 'Ryabitana', 'Karama', 'Rugogwe', 'Karehe']"
},...
And an addition /final-data/extended endpoint, Similar to the /final-data endpoint, but provides additional information on district_id, sector_id, cell_id, form, case_safe_id, opportunity_id, and country.
{
"project_code": "1014107",
"province": "Western Province",
"district": "Rusizi",
"district_id": 36,
"sector": "Giheke",
"sector_id": "3605",
"cell": "Gakomeye",
"cell_id": "360502",
"village": "Buzi",
"village_id": "36050201",
"name": "Buzi",
"type": "Suspended",
"stage": "Rejected",
"sub_stage": "Technical",
"Individuals_directly_served": 0,
"span": 0,
"lat": -2.42056,
"long": 28.9662,
"communities_served": "['Buzi', 'Kabuga', 'Kagarama', 'Gacyamo', 'Gasheke']",
"form": "Project Assessment - 2018.10.29",
"case_safe_id": "a1if1000002e51bAAA",
"opportunity_id": "006f100000d1fk1",
"country": "Rwanda"
},
Merged dataset Endpoints
The two deployed production endpoints /final-data and /final-data/extended follow a slightly different approach as the returned JSON object data required a specific structure in order to be integrated with the web-backend application.
the CSV dataset was loaded with the request library:
request = requests.get(
"https://raw.githubusercontent.com/Lambda-School-Labs/Labs25-Bridges_to_Prosperity-TeamB-ds/main/data/edit/B2P_Rwanda_Sites%2BIDs_full_2020-09-21.csv"
)
buff = io.StringIO(request.text)
directread = csv.DictReader(buff)
And data objects/dictionaries were assembled by looping over directread
# Loop over rows and return according to desired format
for row in directread:
# splitting "communities_served" into list of strings with every
# iteration
if len(row["communities_served"]) == 0:
communities_served = ["unavailable"]
else:
communities_served = list(row["communities_served"].split(", "))
# Set key for dictionary
key = row["project_code"]
# Set output format
output[key] = {
"project_code": row["project_code"],
"province": row["province"],
"district": row["district"],
"sector": row["sector"],
"cell": row["cell"],
"village": row["village"],
"village_id": row["village_id"],
"name": row["name"],
"type": row["type"],
"stage": row["stage"],
"sub_stage": row["sub_stage"],
"Individuals_directly_served": int(row["Individuals_directly_served"]),
"span": int(row["span"]),
"lat": float(row["lat"]),
"long": float(row["long"]),
"communities_served": communities_served,
}
While we have started developing and training of predictive models during the last 2 weeks of this project, we eventually resorted to temporary abandon further model development in favour of working out any kinks and bugs in our DS API, and rather focusing of aiding our web-development teams in delivering solid functionality that could be implemented during the time remaining.
The web application can be found here:
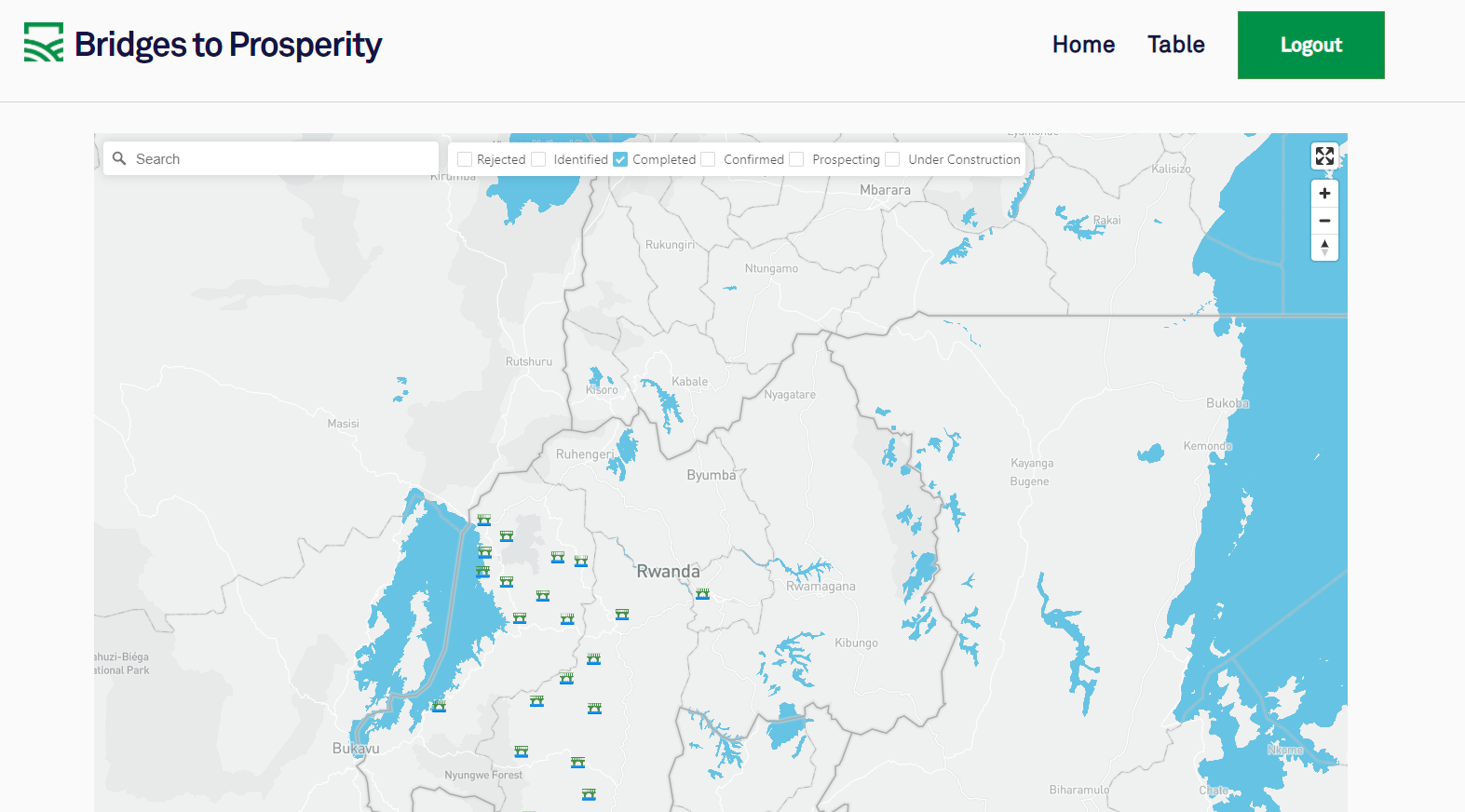
And a detailed description of our API as well as deployment procedures can be found following the repository link above, or here
Lambda Labs Review and Reflection
At this point I’m not fully certain what to think about Lambda Labs, at least the way I experienced it. During the first month of going though the process I got the distinct impression that Labs doesn’t fully know what it wants to be yet, and if it rather focuses on developing a finished product, or focuses on career skills instead, getting participants ready for the application process.
I’m certain these problems will get ironed out with time, as the entire Lambda program and curriculum continues to evolve and advance and eventually leaves its infancy.
Overall my Lambda Labs experience was a positive one. I was fortunate enough to work with a great team of developers, and am especially thankful to my web-dev team members for freely sharing their knowledge on web development concepts, an aspect mostly neglected during the DS core curriculum. At this point I feel more confident in my “cross functional vocabulary,” a major improvement on my path on becoming a well rounded data scientist.
My DS colleagues performed their respective duties outstandingly as well, and I almost wish we had a couple more weeks to add a few additional features, and fully implement predictive modelling capabilities, but that might be something we get to continue on in the future.